Hardware RAIDเป็นการทำ Raid โดยใช้ Hardware Card เข้ามาร่วมทำงาน มีประสิทธิภาพมากกว่า เนื่องจากสามารถจัดการข้อมูลผ่าน CPU บน Card ของตัวเอง
Software RAIDการทำงานของ software RAID จะอาศัย CPU ของเครื่องคอมพิวเตอร์ซึ่งมีหน้าที่ทำงานทุกอย่างของ RAID ทำให้การทำงานช้าโดยเฉพาะเมื่อต้องทำการคำนวณ parity เช่น RAID-3 และ RAID-5 แต่จะมีราคาถูกเพราะไม่ต้องใช้อุปกรณ์พิเศษอื่น และบาง OS (เช่น Linux, NT) ก็มี software RAID ติดตั้งมาให้แล้ว software RAID สามารถทำงานได้ทั้งบน SCSI และ IDE ดิสก์ แต่อาจจะขาดความสามารถบางอย่างไปเช่น hot swap
Hot Spare Diskถ้ามีดิสก์ตัวใดตัวหนึ่งเสีย RAID จะใช้ดิสก์ที่เป็นตัว spare ทำการสร้างข้อมูลขึ้นมาใช้แทนดิสก์ตัวที่เสียไปโดยอัตโนมัติ
Hot Swap Diskถ้ามีดิสก์ตัวใดตัวหนึ่งเสีย ผู้ใช้สามารถถอดเอาดิสก์ตัวนั้นออกมาแล้วใส่ตัวใหม่เข้าไปแทนที่ได้โดยไม่จำเป็นต้องปิดระบบ
เลือก RAID อย่างไร ให้เหมาะสมกับงานปัจจุบัน จะเห็นว่าเทคโนโลยีด้าน Server ได้พัฒนาไปอย่างรวดเร็ว ณ ปัจจุบันนี้เรามีโอกาสได้ใช้ PC ที่มี CPU แตะระดับ เกือบจะ 4.0 GHz แล้ว Main board ก็ เริ่มมี Form factor แบบ BTX ใน ท้องตลาด ด้านกราฟฟิก (VGA) ได้ มีการพัฒนาจาก AGP ไป เป็น PCI-X (PCI Express ) ซึ่งรองรับความเร็วได้สูงกว่า 8 Gb/s ส่วน RAM ก็ไม่น้อยหน้า พัฒนาจนถึง DDR2 ที่ ความเร็ว 6.4 Gb/s แต่เมื่อมองถึง Hard Disk ล่ะที่เห็น จะมีใช้กันอย่างแพร่หลาย ในขณะนี้ก็แค่ SATA ที่ 1.5 Gb/s (150 MB/s) ครั้นจะคอย SATA2 300MB/sนั้น ก็คงต้องรออีกนาน ซึ่ง ถ้าเป็นอย่างนี้ปัญหาก็คงหนีปัญหาคอขวด ที่เกิดบนฮาร์ดดิสต์อย่างหนีไม่พ้น หากต้องเจอสภาพเช่นนี้ก็คงต้องอาศัย เทคโนโลยี RAID เข้ามา เป็นพระเอกขี่ม้าขาวเข้ามา ช่วยเป็นแน่แท้ เพราะนอกจาก RAID จะช่วยทำให้ สมรรถนะโดยรวมของการเข้าถึงข้อมูล (Access) ที่เร็วขึ้นแล้ว มันยังเป็นเทคโนโลยี่ที่ช่วยเพิ่ม ความปลอดภัยของข้อมูลบนตัว ฮาร์ดดิสต์อีกด้วย ซึ่งคงจะได้กล่าวกันในลำดับต่อไป
RAID คืออะไรเมื่อกล่าวถึงระบบจัดเก็บข้อมูลแล้ว สิ่งต่างๆ มักจะไม่ได้เป็นไปตามแผนที่วางไว้เสมอไป ดังนั้นเทคโนโลยี RAID จึงได้ถูกออกแบบ มาเพี่อช่วยแก้ปัญหาที่เกิดขึ้น RAID (Redundant Array of Inexpensive Disks) คือเทคโนโลยีที่มีมานานแล้วสำหรับการสร้าง ลอจิกคอลไดร์ฟ(Logical Drive) หรือเรียกกันทั่วๆ ไปว่า Array ขึ้นมาจากกลุ่มของฮาร์ดดิสก์ (Physical drive) หลายๆตัวมา เชื่อมต่อกันด้วยกัน ซึ่งทำให้มองเห็น อะเรย์หรือลอจิคอลไดร์ฟดังกล่าว เสมือนเป็นฮาร์ดดิสก์ตัวเดียวแต่มีขนาดและความจุ เพิ่มขึ้น โดยซอฟแวร์ และ/หรือ คอนโทลเลอร์ ที่ควบคุม RAID จะคอยบริการจัดเรียงข้อมูลให้อยู่ในรูปแบบของมาตรฐาน RAID แก่ฮาร์ดดิสก์ ทุกๆตัวที่ต่ออยู่ กับอะเรย์นั้น ซึ่งไม่เหมือนกับการที่เพิ่มความจุของฮาร์ดดิสก์ในระบบปกติ แม้จะเป็นการเพิ่ม ความจุ แต่ก็เป็นการเพิ่มจำนวนไดร์ฟไปในตัว เพราะระบบไบออสของเครื่อง ออกแบบไว้เช่นนั้น ทำให้การจัดเก็บอาจจะต้องแยกกันเก็บ และอยู่ในลักษณะที่ไม่ต่อเนื่องกัน ซึ่งเป็นการยุ่งยากในการบริหารจัดการและมีข้อจำกัดอื่นๆ ตามมาอีกมากมาย
RAID มีประเภทและมีวิธีการเลือกชนิดของ RAID อย่างไรหาก จะแบ่ง RAID ตามประเภทของการจัดการจัดเก็บข้อมูลและเทคโนโลยีแล้วจะมีมากกว่า 10 ชนิด แต่ที่นิยมและใช้กันอย่างแพร่หลาย จริงๆจะมีอยู่ราว 5 ชนิดคือ RAID-0, RAID-1, RAID-0+1, RAID-3 และ RAID-5 นอกจากนี้แล้วประเภทของ RAID ชนิดใหม่ที่กำลังได้รับความนิยม เพิ่มขึ้นในขณะนี้คือ RAID-30 และ RAID-50 สำหรับคุณสมบัติและหลักในการทำงานของ RAID ทั้ง 7 ชนิดดังนี้
RAID-0 (Striping)
RAID-1 (Disk mirroring)
RAID-0+1 (S triping/Mirroring)
RAID-3 (Parallel access with a dedicated parity disk)
RAID-5 (Independent access with distributed parity)
RAID-30 ( Striping of Dedicated Parity Arrays)
RAID-50 ( Striping of Distributed Parity Arrays)
BOD- ( Single Drive )
RAID 0 (Striping)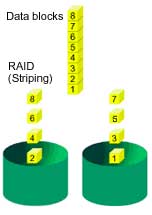
เมื่อได้รับข้อมูลแล้วจะทำการแบ่งข้อมูลเป็นบล็อกมีขนาดเท่าๆกัน แต่ละบล็อก จะกระจายการเก็บไปแต่ละฮาร์ดดิสก์ จะทำให้ประสิทธิภาพการเข้าถึงข้อมูลทั้ง การเขียน / อ่านจะเพิ่มสูงขึ้นมาก เพราะเป็นการเข้าถึงข้อมูลในลักษณะขนาน (ฮาร์ดดิสก์ทุกๆ ตัวจะอ่านและเขียนข้อมูลที่แบ่งส่วนกับการจัดเก็บในเวลา พร้อมๆกัน) อาจกล่าวได้ว่ามันจะทำงานได้เร็วกว่า 2-4 เท่าของการเข้าถึง ข้อมูลสำหรับฮาร์ดดิสก์ที่ต่อใช้งาน แบบปกติ เมื่อนำเอาฮาร์ดดิสต์จำนวน 2 หรือ 3 หรือ 4 ตัวมาต่อกันในลักษณะ RAID 0 แต่ทั้งนี้ทั้งนั้น ยังขึ้นอยู่กับ Access Time, Buffer Cache และความเร็วรอบ ในการ หมุนของจานแม่ เหล็กใน HDD ด้วย ซึ่งเรามักจะเห็นเวลาเค้า ขาย HDD มักจะแข่งกันเรื่อง Spec ของ Access Time ,Buffer Cache และ ความเร็วรอบ
RAID 0 มีประสิทธิภาพอัตราการโอนถ่ายข้อมูลสูงสุด ด้วยเหตุนี้จึง มักเลือกนำเอา RAID 0 ไปประยุกต์ใช้งานกับงานที่ต้องการประ สิทธิภาพด้านความเร็ว แต่ไม่ค่อยคำนึงถึงในเรื่องความปลอดภัย ของข้อมูล อย่างงานด้านการตัดต่อวีดีโอ การแก้ไข , หรือการพัก ข้อมูลก่อนส่งให้แอพพลิเคชั่น (Pre-press) เป็นต้น
สำหรับการ คำนวณขนาดความจุในระบบ RAID 0 สูตรคำนวณง่ายๆ ดังนี้
สูตรคำนวณ ขนาดความจุ RAID 0 = C ( ขนาดความจุของฮาร์ดดิสก์ตัวที่น้อยที่สุด ) x N ( จำนวนฮาร์ดดิสก์ในอะเรย์)
ยกตัวอย่างเช่น เรามีฮาร์ดดิสก์จำนวน 4 ตัว ที่จะนำมาต่อใช้งานในลักษณะ RAID 0 โดยมีขนาดต่างๆกันดังนี้ 100 GB, 120 GB, 200 GB และ 250 GB จำนวนความจุของ Disk array ทั้งหมด เท่ากับ 400 GB (100x4) ไม่ใช่ 670 GB (100+120+200+250) ซึ่งจะเห็นว่าขนาดความจุจริงหายไปถึง 270 GB ดังนั้นในการใช้งาน RAID 0 โดยไม่ทำให้พื้นที่การจัดเก็บหาย ไปจึงควรนำเอาฮาร์ดดิสก์ที่มีขนาดเดียวกันทุกตัว (ถ้าเป็นรุ่นเดียวกันและยี่ห้อเดียวกันได้ก็ยิ่งดีเพราะฮาร์ดดิกส์ทุกตัวจะ ได้ มีค่า Access Time และแคชเมมโมรี่เท่ากัน)
RAID - 1 (Disk mirroring)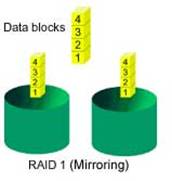
RAID- 1 เป็นการบันทึกข้อมูลลงบนตัวฮาร์ดดิสก์ทั้งสองพร้อมๆ กัน และเป็นข้อมูลเดียว กันเหมือนๆ กันเพื่อสำรองข้อมูลให้ปลอดภัยซึ่งกันและกันในกรณีที่หากมีฮาร์ดดิสก์ตัวใด ตัวหนึ่งเสียขึ้นมาก็จะไม่เกิดการสูญเสียเกิดขึ้นซึ่งเป็นเทคนิคการจัดการความปลอดภัยของข้อมูลชนิดหนึ่งที่เรียกว่า Fault tolerance ที่ได้รับความนิยมในระดับ ENTRY LEVEL ในยุคแรกๆ จนกระทั่งจนถึงปัจจุบัน โดย RAID-1 ต้องใช้ ฮาร์ดดิสก์ 2 ตัว เท่านั้น มาต่อในการ
ใช้ งาน สำหรับการอีกระดับ ความปลอดภัย เป็นเทคนิค ที่เพิ่มตัวคอนโทลเลอร์ คือเป็นการใช้คอนโทลเลอร์ 2 ตัวเพื่อป้องกันคอนโทลเลอร์เสีย โดยมีสถานการณ์ทำงานทั้งสองตัวเป็น (Active/Active) หรือ (Active/Standby) กรณีเป็น Active จะทำงานตลอดเวลา ส่วน Standby จะใช้งานเมื่อคอนโทลเลอร์ตัวแรกเสีย ถ้ามีการใช้ 2 คอลโทลเลอร์จะทำให้เพิ่มประสิทธิภาพในการอ่าน/เขียน และทนต่อสภาวะเสียได้อีกระดับ
ในกรณีที่ฮาร์ดดิสก์ตัวใดตัวหนึ่งในอะ เรย์เสีย ตัวที่ทำหน้าที่เป็นตัวกระจกเงา (Mirror) ที่มีข้อมูลเหมือนกันทุกอย่าง ก็จะทำหน้าที่แทนในทันทีทันใด โดยไม่ทำให้การทำงานเกิดการสะดุด อีกทั้งถ้าหากเราเพิ่มฮาร์ดดิสก์สำรอง เป็นฮาร์ดดิสก์ตัวที่ 3 (แสตนบาย/ แบ็คอัพ) ซึ่งเป็นฮาร์ดดิสก์ที่ไม่ถูกใช้งาน ในการทำงานปกติ เมื่อเกิดฮาร์ดดิสก์ใน Mirror เสีย ฮาร์ดดิสก์ตัวสำรอง จะถูกจับคู่เป็น Mirror แทนตัวที่เสียอัตโนมัติ RAID -1 มีการทำงานเรียก อีกอย่างหนึ่งว่า Data redundancy แนวความคิดที่นำ RAID-1 ไป ประยุกต์การใช้งานจึงเกี่ยวกับงานที่ให้ความสำคัญกับข้อมูลเป็นหลัก ไม่เน้นเรื่องของความเร็วหรือประสิทธิภาพการเข้าถึงข้อมูล สำหรับการ คิดขนาดความจุของ RAID-1 มีหลักการคำนวณดังนี้
สูตรคำนวณ ขนาดความจุ RAID- 1 = ขนาดความจุของฮาร์ดดิสก์ตัวน้อยที่สุดของคู่ฮาร์ดดิสก์ที่นำมาทำ RAID
ยกตัวอย่างเช่น กรณีนำฮาร์ดดิสก์ ทั้ง 2 ตัวที่มีความจุ 100 GB และ 250 GB นำมาทำเป็น RAID- 1 จะได้ความจุรวมเท่ากับ 100 GB ดังนั้นในการใช้งาน RAID-1 จึงควรนำเอาฮาร์ดดิสก์ที่มีขนาดเดียวกันทุกตัว (ถ้าเป็นรุ่นเดียวกันและยี่ห้อเดียวกันได้ก็ยิ่งดี) ก็จะทำให้เกิดการสูญเสียพื้นที่ว่าง เปล่าน้อยที่สุด เนื่องจากการทำงานใน RAID-1 ซึ่งจะต้องมีการเขียนข้อมูลซึ่งที่เหมือนกันลงบนฮาร์ดดิสก์ ทั้ง 2 ตัวและจะต้องมีขบวนการตรวจสอบความเหมือนกันของข้อมูลบนฮาร์ดดิสก์ทั้ง 2 ตัวอยู่ตลอดเวลา ดังนั้นประสิทธิภาพด้านความเร็วในการเขียน / อ่านข้อมูลจึงต่ำกว่า RAID-1 และต่ำกว่าการต่อใช้งานฮาร์ดดิสก์แบบปกติที่ไม่ใช่ RAID อย่างแน่นอนเพียงแต่ RAID-1 จะได้ประโยชน์ในเรื่องความปลอดภัยของข้อมูลดังที่ได้กล่าวไปแล้วเท่านั้น
RAID -0+1 (S triping/Mirroring)
RAID- 0+1 หรือ RAID-10 ได้นำข้อดีหรือคุณสมบัติเด่นของ RAID-0 ที่มีประสิทธิภาพในการเข้าถึงข้อมูลที่รวดเร็ว และ RAID-1 ที่มีความ ปลอดภัยของข้อมูลมาประสานรวมกัน เพื่อให้ผู้ใช้ได้ทั้งความเร็วและความปลอดภัยในการใช้งาน RAID-10 มีชื่อเรียกอีกอย่างหนึ่งว่า “Dual data redundancy” โดย จำนวนฮาร์ดดิสก์ที่จะนำมาทำระบบ RAID-10จะต้องมี 4 ไดร์ฟ อย่างเดียวเท่านั้น เช่นการคำนวณขนาดความจุของอะเรย์รวมคิดจากขนาดของอะเรย์ RAID - 0 เพียงชุดเดียว ( ในกรณีที่มีขนาดของอะเรย์ของ RAID - 1 ทั้ง 2 ชุดเท่ากันเช่น เมื่อนำเอาฮาร์ดดิสก์ขนาด 120 GB 4 ไดร์ฟ มาทำ RAID - 0+1 ก็จะได้ RAID - 0 ขนาด 240 GB จำนวน 2 ชุด (240 GB/240GB)แต่ RAID 0 ทั้ง 2 ชุดนี้นำมาทำ RAID - 1 (mirror )จึงทำให้ได้ความจุเพียงแค่ชุดเดียว คือ 240 GB เท่านั้นส่วนการคิดความจุรวมของ RAID- 0+1 มีสูตรดังนี้
สูตรคำนวณ ขนาดความจุของดิสก์อะเรย์ของ RAID 0+1 = C
( ขนาดความจุฮาร์ดดิสก์ตัวที่เล็กที่สุด) x N ( จำนวนครึ่งหนึ่งของจำนวนฮาร์ดดิสก์ทั้งหมด)
ยกตัวอย่างเช่น กรณีที่นำฮาร์ดดิสก์จำนวน 4 ตัวซึ่งมีความจุ 200 GB 2 ตัว และ ความจุ 250 GB 2 ตัว นำมาทำเป็น RAID- 0+1 ดังนั้นเราจะได้ความจุรวมทั้งหมดเป็น 400 GB (200 GB x (4/2) เป็นต้น เรามาดูหลักการของ Dual Data Redundant ในการ Redundant ข้อมูล โดยการต่อ HDD ในรุ่น FastTrak 100 ทำ RAID 10 ว่า เมื่อเกิด HDD ลูกใดลูกหนึ่งเสียแล้ว จะทำให้ อะเรย์ Off Line
RAID-3 (Parallel access with a dedicated parity disk)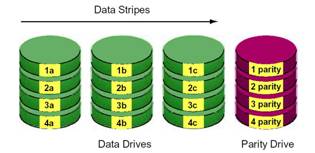
RAID-3 ที่มีการจัดการของข้อมูลที่ถูกจัดเก็บลงบนฮาร์ดดิสก์ (อย่างน้อยต้องใช้ 3 ตัว) ซึ่งจะมีฮาร์ดดิสก์ตัวหนึ่งถูกใช้เก็บเฉพาะพาริติ้ เพียงอย่างเดียว ซึ่งข้อมูลพาริติ้เป็นข้อมูลที่ใช ้ในการตรวจสอบความถูกต้องของข้อมูล ส่วนข้อมูลที่ใช้งานจริงจะเก็บอยู่ในฮาร์ดดิสก์ ตัวที่เหลือ โครงสร้างของ RAID-3 จะช่วยใน การเพิ่มประสิทธิภาพในการอ่าน/เขียนข้อมูล เพราะเป็นการเข้าถึงข้อมูลด้วยฮาร์ดดิสก์หลายๆ ตัวในขณะเดียวกัน พร้อมๆ กัน นอกจากความเร็ว ที่เพิ่มขึ้นก็ยังมีระบบความปลอดภัยที่เพิ่มขึ้น ของข้อมูลด้วยการตรวจสอบข้อมูลพาริติ้
ในกรณีที่ฮาร์ดดิสก์ตัวใดตัว หนึ่งเกิดเสียขึ้นมา ข้อมูลที่สูญหายซึ่งอยู่ภายในฮาร์ดดิสก์ตัวที่เสีย เมื่อนำฮาร์ดดิสก์ใหม่มาแทนที่ ระบบจะสร้างข้อมูลขึ้นมาใหม่ (Rebuild Data) โดยการคำนวณทางตรรกศาสตร์ ซึ่งใช้ข้อมูลพาริติ้และข้อมูลของฮาร์ดดิสก์ที่เหลือมาทำการคำนวณ จนได้ข้อมูลกลับมาโดยครบถ้วนดังเดิม วิธีการคิดความจุของ RAID-3 มีสูตรคำนวณง่ายๆ ดังนี้
สูตรคำนวณ ขนาดความจุของดิสก์อะเรย์ของ RAID-3 = C ( ขนาดความจุฮาร์ดดิสก์ตัวที่เล็กที่สุด ) x N ( จำนวนฮาร์ดดิสก์ทั้งหมด-1 )
ตัวอย่างเช่น กรณีที่นำฮาร์ดดิสก์จำนวน 5 ตัวซึ่งมีความจุ 200 GB 2 ตัว และ ความจุ 250 GB 3 ตัว นำมาทำเป็น RAID-3 ดังนั้นเราจะได้ความจุรวมทั้งหมดเป็น 800 GB (200 x (5-1)) เป็นต้น ส่วนที่ต้องหักจำนวนฮาร์ดดิสก์ออกหนึ่ง เพราะฮาร์ดดิสก์นั้นไม่ได้เก็บข้อมูลใช้งานจริง แต่มันเป็นฮาร์ดดิสก์ที่สำหรับเก็บข้อมูลพาริติ้ เพื่อสร้างระบบความปลอดภัยของข้อมูลที่เก็บ
RAID-3 มีเทคนิคตรวจสอบความถูกต้องของข้อมูล( Spindle synchronization )ในการอ่าน / เขียนข้อมูล ซึ่งการเขียน / ปรับปรุงข้อมูลจะมีการเขียนพาริติ้ ซึ่งเก็บในเพียงหนึ่งไดร์ฟ ทุกครั้งอันก่อให้เกิดคอขวดที่ฮาร์ดดิสก์ตัวดังกล่าว
โดยทั่วไปแล้ว RAID-3 มักจะถูกนำไปประยุกต์ใช้งานกับงานที่ต้องการเขียน / อ่านข้อมูลแบบที่มีการสุ่มน้อยกว่า (Lower random) เพราะมิเช่นนั้นแล้วฮาร์ดดิสก์ตัวที่ใช้เก็บข้อมูลพาริตี้ จะทำงานหนักสำหรับการคำนวณซ้ำ และจะมีผลให้มีประสิทธิผลโดยรวมด้อยลง
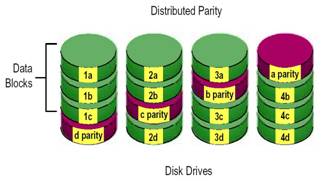
RAID-5 (Independent access with distributed parity)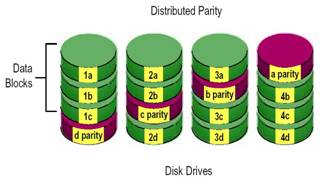
ลักษณะการและการทำงานของ RAID-5 จะมีลักษณะคล้ายคลึงกับ RAID-3 เว้นแต่จะต่างกันตรงที่ในระบบ RAID-3 จะเก็บข้อมูลพาริตี้ และข้อมูล ใช้งานไว้ใน ฮาร์ดดิสก์แยกออกจากกันในขณะที่ RAID - 5 นั้นการเก็บข้อมูลพาริตี้และข้อมูลใช้งานนั้นจะมีการกระจายกันจัดเก็บทั่วทุก ตัวของ ฮาร์ดดิสก์ในลักษณะหมุนเวียนเรียงลำดับกัน การจัดเก็บโดยวิธีนี้ จะเป็นการช่วยแก้ปัญหาคอขวดที่มักจะเกิดขึ้นกับกรณีเกิดการเขียนข้อมูล แบบสุ่ม(Random write) ใน RAID 3 อยู่เนื่องๆ อาจกล่าวได้ว่าใน ปัจจุบันการประยุกต์ใช้งาน RAID - 5 มักจะได้รับความนิยมมากกว่า RAID - 3 เพราะประสิทธิภาพโดยรวมของ RAID - 5สูงกว่า RAID - 3 นั่นเอง ส่วนการทำพาริติ้ ข้อมูลทำโดยใช้ฟังก์ชัน แอกคูซีพออล์ (Exclusive OR)
RAID-5 มีประสิทธิภาพโดยรวมสูง ซึ่งมีปัจจัยคือ ประสิทธิภาพต่อราคาดีที่สุด, การทำงานมีเสถียรภาพสูงและมีระบบความปลอดภัยเมื่อมีฮาร์ดดิสก์ตัวใดตัวหนึ่ง ในอะเรย์เสียโดยทั่วไปแล้วจะ RAID-5 มักถูกนำไปประยุกต์ใช้งานกับการเก็บไฟล์, ดาต้าเบส, แอพพลิเคชั่นและเว็บเซิฟเวอร์ ทั้งในระบบอินเตอร์เน็ตและระบบอินทราเน็ต
สำหรับสูตรการคำนวณความจุของอะเรย์รวมจะเหมือนกับ RAID-3 นอกจากนั้นแล้ว RAID-3,RAID-5 ยังรองรับการทำงาน Hot Swapping/redundant หมายถึง ถ้าหากในเวลาใช้งานฮาร์ดดิสก์ ตัวใดตัวหนึ่งเสีย โดยทันทีทันใด นอกจากระบบจะสามารถทำงานได้อย่างต่อเนื่อง ตามปกติกับข้อมูลบนฮาร์ดดิสก์แล้วยังสามารถถอดเอาฮาร์ดดิสก์ตัวที่เสียออกใน ขณะที่ระบบ RAID ยังคงทำงานอยู่โดยไม่ต้อง Down ระบบ พร้อมทั้งเอาฮาร์ดดิสก์ตัวใหม่เข้าไปแทนที่ จากนั้นระบบทำการสร้างข้อมูลขึ้นมาใหม่บนฮาร์ดดิสก์ตัวใหม่จบครบถ้วนอย่าง อัตโนมัติ โดยที่ผู้ใช้งานไม่ต้องจัดการกู้ข้อมูลตัวเองเลย
ปัจจุบันทั้ง RAID-3 และ RAID-5 สามารถนำไปประยุกต์ใช้กับดิสก์อะเรย์ที่มีจำนวน ฮาร์ดดิสก์รวม ตัวใน 1 ดิสก์ อะเรย์ซึ่งนอกจากจะเพิ่มประสิทธิภาพของแอคเซสข้อมูลโดยรวมและขยายขนาดความจุของ ดิสก์อะเรย์ได้อย่างเต็มที่แล้ว ยังสามารถนำเอา 1 ในจำนวน 8-15 ตัว ของฮาร์ดดิสก์เหล่านั้นมาทำเป็น ไดร์ฟสำรอง ( Spare drive) นั่นหมายความว่า โดยปกติ Spare drive ตัวดังกล่าวจะยังไม่ถูกใช้งานในสภาวะปกติ จนกว่าที่จะมีฮาร์ดดิสก์ ตัวใดตัวหนึ่งในดิสก์ อะเรย์ เสียขึ้นมา มันก็จะแอคทีฟและทำหน้าที่แทนที่ตัวที่เสียอัตโนมัติโดยทันที
เป็น RAID ตัวใหม่ ที่เริ่มจะได้รับความนิยม เพิ่มขึ้นเรื่อยๆ ในขณะนี้ โดยอาศัยหลักการทำงานผสมผสานกันระหว่าง RAID - 3 และ RAID - 0 เข้าไว้ด้วยกันเป็นหนึ่งเดียว RAID-30 จะเป็นการใช้ข้อดีของ RAID-0 ที่มีประสิทธิภาพในการเข้าถึงข้อมูลที่รวดเร็ว และ RAID- 3 ที่มีความปลอดภัยของข้อมูล มาประสานรวมกัน โดยมองโครงสร้างไดร์ฟทั้งหมดเป็นแบบ RAID- 0 คือมีการแยกไดร์ฟเป็นสองชุด โดยแต่ละชุดจะทำการเก็บข้อมูลแบบ RAID-3 ซึ่งข้อมูลที่เข้ามาเก็บจะถูกแบ่งเป็นบล็อก กระจายเก็บลงบนฮาร์ดดิสก์แต่ละชุด ซึ่งแต่ละชุดมีการทำพาริติ้ข้อมูล แบบ RAID-3 คือทำแล้วเก็บข้อมูลพาริติ้ไว้ที่ไดร์ฟเดียวในแต่ละชุด (สมมุติมีฮาร์ดดิสก์ 6 ตัว ทำเป็น RAID-30 จะมีฮาร์ดดิสก์ที่เก็บข้อมูลที่ใช้จริง 4 ตัว อีก 2 ตัวใช้เก็บเป็นพาริติ้ไดร์ฟของแต่ละชุด)
source :
https://bit.ly/3s35g8R
 กระทู้เมื่อเร็วๆ นี้
กระทู้เมื่อเร็วๆ นี้